Irina Higgins is a senior research scientist at DeepMind, and has a background in neuroscience.
The second presentation at this event largely focused on telling a story about DeepMind’s development of AlphaGo – using this as a vehicle to explain DeepMind’s approach and give insights into its culture.
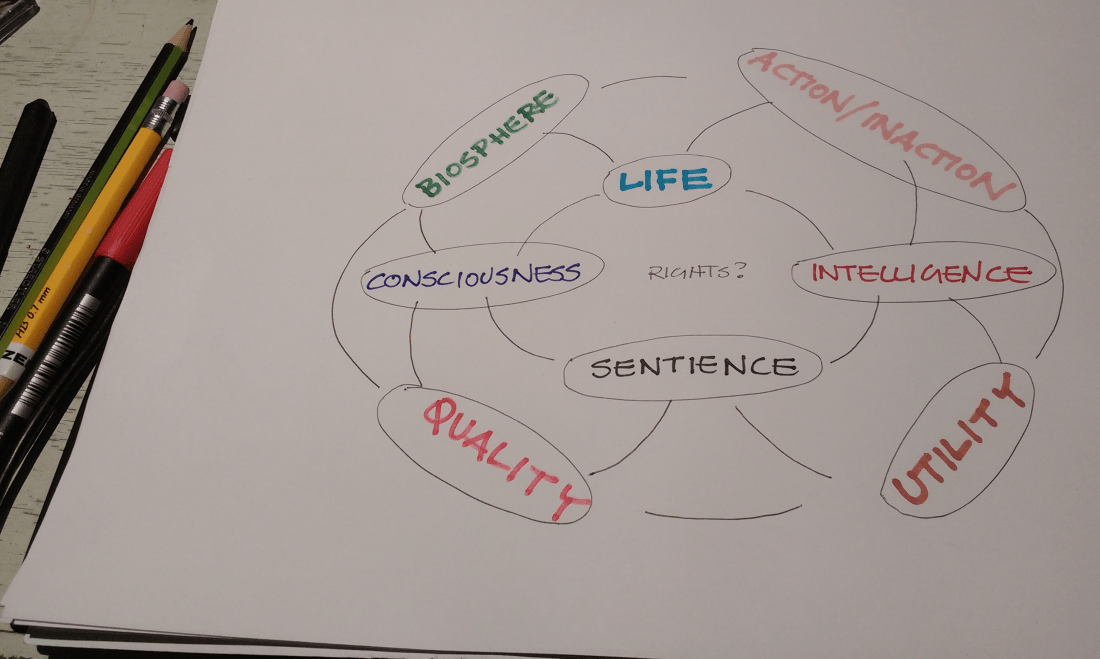
She told us that DeepMind now has 300 scientists, and was keen to emphasise the high-minded aspirations of the organisation – from its mission statement;
Solve intelligence. Use it to make the world a better place.
to its ‘intentionally designed culture’, which aims to mesh the best aspects of industry and academia; the intense focus and resources of the former with the curiosity driven open-ended approach of the latter.
DeepMind’s operating definition of general intelligence is apparently; Continue reading “New Scientist Artificial Intelligence day – Session One; the Mainstream – Irina Higgins”
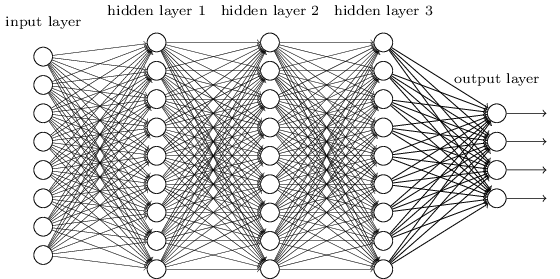


 This
This