
Irina Higgins is a senior research scientist at DeepMind, and has a background in neuroscience.
The second presentation at this event largely focused on telling a story about DeepMind’s development of AlphaGo – using this as a vehicle to explain DeepMind’s approach and give insights into its culture.
She told us that DeepMind now has 300 scientists, and was keen to emphasise the high-minded aspirations of the organisation – from its mission statement;
Solve intelligence. Use it to make the world a better place.
to its ‘intentionally designed culture’, which aims to mesh the best aspects of industry and academia; the intense focus and resources of the former with the curiosity driven open-ended approach of the latter.
DeepMind’s operating definition of general intelligence is apparently;
a single algorithm that can learn and adapt to achieve human level performance across the broadest set of tasks.
To this end, DeepMind have concentrated on the development of general purpose learning algorithms – systems which ‘learn’ automatically from raw inputs – where only the structure of the system is pre-programmed, not its characteristics, and where there are no pre-defined symbolic interpretations for the input data.
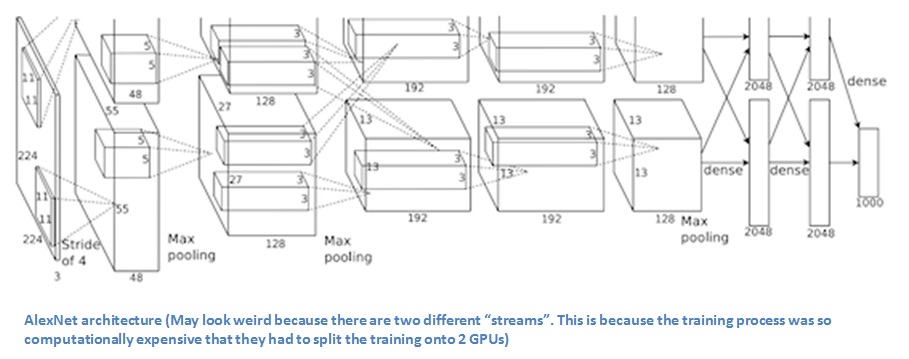
Higgins referenced AlexNet as a foundational piece of work in this area – a highly successful 2012 image recognition system using a ‘deep convolutional neural network’, which anchored the current explosion of work in neural networks.
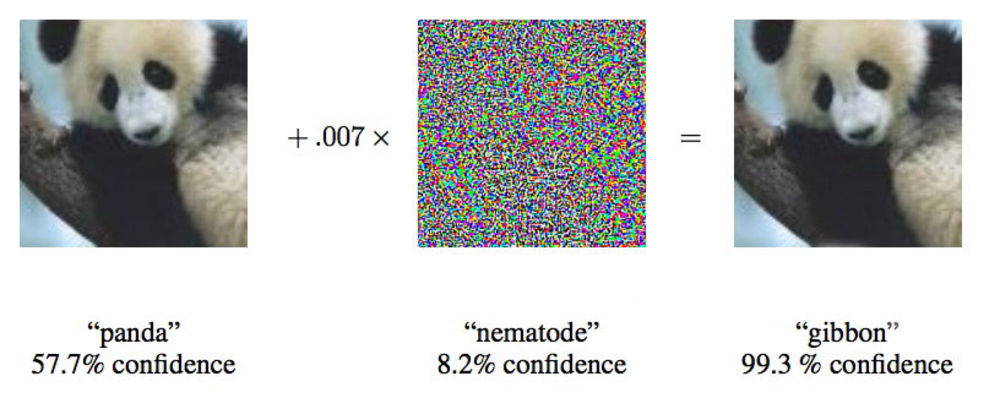
She then showed us that, successful as such approaches are, however modelled on biological neural nets they might be, they do not at all work in the same way that our brains do; an image of a dog was identified as such by a trained neural net. Then a light scattering of apparently random pixels was overlaid – the resulting picture essentially identical; obviously a dog to human eyes, but identified with 99% confidence as an ostrich by the same AI system [1,2,3].
DeepMind’s approach adds Deep Reinforcement Learning to this approach. Another incorporated technique confirms Lucas’ observation that much of the theoretical groundwork for current success is decades old – application of the ‘Back Propagation of Error‘ technique, dating from 1986 (the paper linked refers to an earlier description of the same algorithm from 1974 – ancient history in computer terms).
In this way DeepMind hopes to more closely approach the ‘grounded cognition’ of an embodied intelligence, based in a ‘sensorimotor reality’.
Confirming Lucas’ focus, Irina also emphasised the value of games as a development environment for AI, offering the following benefits;
- absence of testing bias (use of existing human games guarantees that the results are relevant to human ideas of intelligence),
- unlimited data available,
- parallel testing is possible,
- progress metrics are easy to determine.
Moving on to the specific history of AlphaGo, Higgins showed some videos of the foundational project, during which the DQN system ‘learned’ to play a number of Atari video games on the basis only of access to the pixel display array, the possible controls, and the score, but without any reference to previously collected training data or prior modelling. Remarkably, the approach resulted in the machine learning to play most of the 49 games to human level, and in several to super-human level – in one remarkable instance (Breakout), discovering and mastering a highly effective technique unknown to the researchers themselves (although known to expert players).
DeepMind then set themselves the challenge of Go – a game which many AI experts had predicted would not be mastered by AI players for decades. The AlphaGo system is more complex than the Atari-playing system, and was trained extensively on prior data. Additional modules were used to reduce the number of move options studied to a manageable number, but without over-constraining the scope of analysis. AlphaGo then played millions of games against itself, on numerous parallel machines, improving its ability to predict the outcome of moves within a ‘tree’ of future possibilities too immense ever to be exhaustively traced.
Higgins showed us a video of the European go champion, Fan Hui, who had secretly played a match against AlphaGo prior to the public match against Less Sedol. He lost five nil, to his enormous surprise. Interestingly, Hui considers the encounter to have been valuable, and to have made him a better player.
The video of AlphaGo making its famous ‘Move 37’ and going on to win the tournament against Lee 4-1 came as no surprise to the audience, of course, but we were left with an impressive graph showing the effect of giving control of the cooling equipment of a Google data centre over to a DeepMind system; running costs were halved, and reportedly the savings paid for the entire AlphaGo project. [Aside – you thought that the internet was somehow low energy? Approximately half of the energy costs of running data centres is in cooling them; the world’s data centres last year consumed more energy than the UK.]

2 thoughts on “New Scientist Artificial Intelligence day – Session One; the Mainstream – Irina Higgins”