Last night I listened to this feature on the excellent BBC World Service – Hacking the Vote – pegged on claims by companies hawking their services to political parties that they know enough about a great many individuals to be able to create specific pyschological profiles and thus enable carefully crafted messages to be shown to them, to get them to vote for the candidate paying for the service.
The shocking reminder of the extent to which data is being collected on all of us and put to murky use in the shadows prompted this post.
It’s not about data privacy, particularly – although I personally make my online life stupidly difficult by using a vpn, by installing the anti-tracking, anti java-script, anti adverts, anti-everything extensions I can find to my browsers in an attempt to at least put some road-bumps down for those who would treat my as a statistical profit centre. With the self-defeating result that half the sites I use won’t work unless I grant them freedom to do it all anyway.
It’s about a way that we, as individuals, might be able to use that data for our own purposes. If it’s all being collected and used to manipulate us anyway, why shouldn’t it work for us, a little?
Aggregated trust scores
There have been several attempts at building tools that provide reputation metrics, trust scores – think credit ratings on steroids.
The idea being that individuals will sign up to aggregator sites, and give them access to various kinds of trust/social standing scores. The aggregator sites will then publish trust metrics on individuals, to be used by all sorts of people. Employers, potential service users, lenders, contacts, dating matches.
If anyone manages to crack this (it’s not easy – see this dead indiegogo site for peeple), then individuals will spend more effort curating these than they do on their credit rating. Lawsuits will be brought over harsh ratings using defamation laws drafted decades before the internet was even imagined.
The trust aggregator metric that is itself trusted will be the locus of immense influence. If that doesn’t already sound scary, there’s another big problem.
Single figure aggregators are too simplistic to represent us
My reliability as (say) a contributor to open-source coding projects has no obvious bearing on my reliability at repaying bank loans, or as a potential life partner, or as a writer, or as an event organiser. These things relate to different aspects of my personality. None of them will tell you about my politics or the refinement of my palate.
People are complicated.
Cory Doctorow wrote a novel – Down and Out in the Magic Kingdom – about a post-market society with a reputation economy based on a single metric – which he called ‘whuffie’. He later wrote that this would be a Bad Thing – that ‘Whuffie would be a terrible currency‘ – that it would become a ‘popularity contest in which the rich always get richer’. It’s worth reading the post he wrote – it’s quite scathing, and I don’t disagree with any of it. If you use eBay, you might want to read the part about the ‘long con’.
But it’s all about single-figure aggregate scores – about attempting to sum up a human being with a single number that purports to convey their public worth.
Reputation scores are coming anyway
Consider the current furore about ‘fake news’. Lots of people are getting excited about ways of dealing with this problem – the social network firms are being bashed, hackers are working up insta-fact checkers – it’s a regular storm in a teacup.
There has always been fake news – the Zinoviev letter which was used to raise anti-communist feeling in the UK in the 1920s, and the Blood Libel lies about Jews are only the most famous.
Ultimately, what we seek is the provenance of news – who originated the story? Do we trust them? To deal with fake news, we have to trace stories to their source and answer that question for ourselves – or more likely, trust some-one else’s answer, as we just don’t have the time. Do I know whether Snopes is always right? Would I ever dig deeper than Snopes? Very unlikely – I trust Snopes.
Trust is the tool we use to move forward without checking every detail of everything. Where we have prior direct knowledge or experience, we can decide whether to trust on the basis of that evidence. But our world is growing exponentially wider and more interconnected, bringing us into contact and into exchange relationships with people and organisations about whom we know almost nothing.
Of course, this is one function of money. Money is in one sense distributed trust – trust in the stability of the society that uses the currency. ‘Wisdom of the crowd’ trust, embodied in portable units, an incredible human invention.
Unfortunately for us, though, money is a single value metric that tells us almost nothing about what we’re trusting. It’s an all-or-nothing trust that is asked of us. Trust that the money wasn’t earned off the backs of child labour, that it isn’t a forgery, that inflation isn’t about to run mad, and, most fundamentally, that the rules haven’t been stacked in someone else’s favour – which of course they have been. Douglas Rushkoff’s book, Life, Inc. documents the history of money, showing how the rules of the game have been set from the start so that its primary purpose is to extract value, rather than enable speedier transaction turnover – which is the ostensible function. But that’s a different post.
So if money’s trustworthiness is compromised, but we don’t want to give up the new possibilities the interwebs offer, and we’re worried about fake news, and even more worried about the creepy activities (listen to the BBC podcast linked above for more creepiness) of companies like Cambridge Analytica, who claim to;
use data modeling and psychographic profiling to grow audiences, identify key influencers, and connect with people in ways that move them to action,
- then what can we trust?
One answer that is being pushed hard is blockchain. Blockchain is many things, but the single characteristic that you read again and again is that it enables reliable exchange ‘without the need for trust’. Think about that. Exchange without trust. The idea is that whatever the rules about exchange are, they are encoded in software, as ‘smart contracts’ – contracts which, on the basis of digital inputs, will automatically be executed and recorded if the specified conditions are met.
So, in one example I saw, all the contributors to a movie project would be connected via a vast web of these smart contracts, so that when you stream it at home, your small payment is automatically allocated out, exactly in accordance with the agreements, to all the eligible individuals. No need for book-keepers, accountants – the whole thing is dealt with in one go, and etched in the immutable digits of the blockchain.
The number of ways in which this is a foolish proposition exceeds the scope of this post, but if we concentrate on the issue of trust, we can see one of them straight away. Who makes the contract? Who encodes the contract? Who do we trust to audit the contract? Because we’re certainly not going to be doing this ourselves – not for our miniscule share of a 4.99 streaming fee, we’re not.
So we need to trust people after all. Our agent, who makes the deal, our lawyer, who writes the contract, the coders who instantiate the contract in the blockchain code. In fact, it rather looks as if we have added this last category to the list of people we needed to trust already – thus increasing the problem, if anything. I mean, it’s not as if coders are infallible or universally saintly, right?
Don’t get me wrong – I’m not saying blockchains are useless – just that they aren’t the answer to life, death, the universe and everything. And certainly not to the online trust problem.
At the end of the day (well, the day before the singularity, anyway), it always comes down to people. To trusting people you don’t know. And we always do that based on reputation – mostly in the messiest, most amateurish of ways. Ways which work less and less well the less context we have for making the judgement.
Which brings us back to the starting point, but with some more nuanced understandings.
Reputation flowers
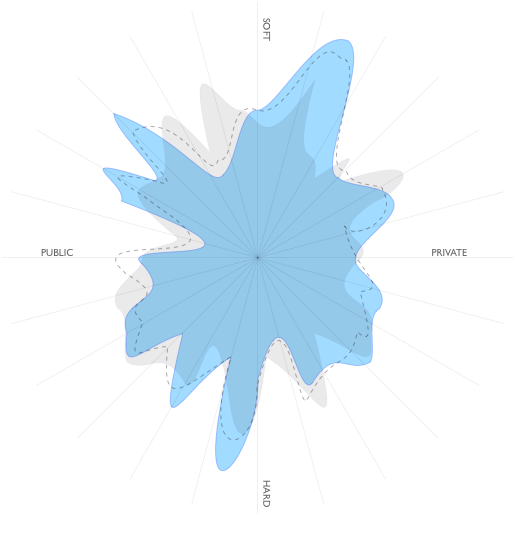
A Reputation Flower is an aggregate of many, many reputational indicators, of many kinds, summed on many separate axes, each concerned with some specific aspect.
Many of these indicators will be public (the status of your driving license, your examination record, your ebay score, number of twitter followers, how many videos you have posted on YouTube and how many views they have received), and some you will have consented to release (perhaps your credit rating, your salary, your relationship status, your political party membership). Some will be hard metrics, some will be softer.
They’ll be graphed to produce your ‘flower’, with axes grouped so that the shape of the flower will become a pattern that people will be able to understand intuitively – a head-teacher’s will have a different characteristic shape to that of a politician, a plumber, a professional, a coder. And the flower of a coder who skis and has a busy night life will look different to that of one who is a heads down, headphones-on all-nighter. Different quadrants will relate to different aspects of your life. If you’re intensely private, one or more quadrants may be blank.
Data will be continuously updated. If you permit it, people will be able to watch your flower as it evolved over years. Characteristic patterns of this evolution will also be recognisable – making fraudulent flowers hard to produce.
You may choose to permit your flower to be used interactively – to let people zoom in on sectors, look at the fine detail (what is this person’s eBay score?).
At this point I imagine some readers recoiling in horror, and indeed I sympathise. But the scary truth is that in reality, all of this data is already being graphed. Cambridge Analytica, mentioned above, apparently boast that they hold thousands of unique data-points about almost every US citizen, on the basis of which they purport to be able to imply all sorts of things. This data is already being mined, being used – in the dark, in secret, by big corporations. And you are getting no benefit from it. And as was pointed out in the BBC program, even if we enacted the most stringent data privacy laws, most of us would find ourselves ticking the opt-out boxes – for the sake of free Facebook, free Google, for the sake of people being able to find our Tweets, our blog posts, our selfies…
For many, many reasons – not least the blithe profligacy with which even the most tin-foil hatted of us strews data points in our wake – privacy is dead. We can bury our heads in the sand and deny the truth of it (while happily cruising amazon for bargains, tinder for partners, facebook for gossip, walking around with our ‘phones sending out ‘hello I’m here’ signals over the wifi every 60 seconds), or we can develop new attitudes, new tools, new skills, and take ownership of our public selves.
Because otherwise someone else will.

Note that a reputation system like Quantified Prestige could enable peer-generated data that could be used for reputation flowers. See: https://forum.fractalfuture.net/t/quantified-prestige-short-introduction/176/12
Also, reputation flowers as presented here depend on the visibility of the data. You can only visualize a reputation flower, if you have access to the required data. Of course, if anyone had access to all kinds of data about everyone else, everyone would see the same reputation flowers, but until we are at that point, reputation flowers will be personalized to those who view them. In a network with n persons, there will generally be n * n reputation flowers.
LikeLike
Hi Michael!
The usefulness of the visual characterisation of reputation depends on the superlative ability of humans at pattern recognition.
The suggestion is that, after some experience, one might be able to recognise the characteristic of flowers typically pertaining to celebrities, say, as distinct from politicians, as distinct from academics. To distinguish between introverts and extroverts, between overachievers and underachievers.
At the same time, the marks of individuality – deviations from expected shapes – would attract special interest, and invite investigation – thus allowing rapid higher-level appreciation of what it is about an individual that marks them out from their stereotype.
A key attribute of this visual approach is that (for the time being, at least) humans will be better at this than machines.
In order for patterns to become recognisable in this way, it would be important for the explosive variety you describe to be avoided. This would be on the basis of some public, standardised database of metrics (which could well be, or include the Quantified Prestige approach you describe), and some set of standardised, public graphing schemas.
Perhaps particular social media websites would develop popular representation schemas which would be optionally displayed alongside one’s avatar.
Specialist schemas would no doubt be used by different groups for different purposes – as happens at the moment with the hidden data. but at least one would be able to view one’s own metrics through public versions of those schemas, and have the chance to curate one’s flower, as in;
“This is the schema which my desired university publicly states it uses to inform itself about candidate’s wider character, and this is what the mean, mode and extreme percentiles on the bell-curve of accepted candidates flowers’ look like. It seems I might be wise to improve my scores in physical activity, or in community engagement, given that I’m not sure I can improve on my subject grades.”
The different outlines on the illustration (which is of course purely imaginary) are intended to suggest interesting possibilities with the stored data.
For instance, one might ask for an animated sequence of the flower to be displayed, showing its development over the previous five years. This would make fake accounts much harder to develop.
One might also find that operations analogous to those applied to stock-market charts, like rolling 3 month averages, minimum/maximum bars and the like might be useful.
All of this is as terrifying as it is interesting. But I repeat – all this data is being used anyway – without our knowledge, and without us having the slightest opportunity to understand how.
We owe it to ourselves to consider ways to change the balance of power.
LikeLike