Raoul Vaneigem said;
Everything has been said yet few have taken advantage of it. Since all our knowledge is essentially banal, it can only be of value to minds that are not.
But he wrote this before the internet existed. Today, we might add ;
… and is only discoverable by those with excellent search skills and a willingness to plough through endless irrelevance.
Finding information that meets your needs, is written in a language you understand, on the basis of assumed knowledge that you already possess is not at all easy – despite the cornucopia that is the internet. Or is it, because of the cornucopia…?
The problem applies in reverse for producers of content. How will your (my!) little gem of insight ever be seen by more than a few?
In theory, this problem is addressed by metadata, explicit and implicit, and by the sophisticated algorithms used by search-engines. In practice, these are insufficient to deal with the unimaginable enormity of the flood of information that the internet has unleashed. On any topic which is of even minority interest, the quantity of information available to a search engine is lunatic in its over-supply – tens of thousands of results on even obscure searches – who ever looks beyond the first or second page? And yet a small change in the query text can result in an entirely different set of results – results which were probably in the first hundred or so items of the first search.
Recognising the increasing character of the internet as a huge, structureless collection of data, Tim Berners-Lee coined the term ‘Semantic Web‘ as long ago as 2001. The idea was that information on the web should increasingly be machine navigable by means of highly structured metadata. Key concepts within the content would be marked-up as ‘triples’, of Subject :: Predicate :: Object, such as: Germany :: has Capital :: Berlin. These triples can connect objects in chains, so that Germany would be identified as a country, countries would be identified as having capitals, capitals identified as being cities, cities as having populations, and so on. These relationships can be captured to develop ontologies – collections setting out the concepts/objects, the range of characteristics they have and the relationships between them, usually within a specific domain.
The more information that is marked up in this way, the more possible it will be for machine reasoning systems to deliver relevant and structured content in response to searches, and to correlate information across data sources.
That’s the dream, anyway. Although there is obviously a fair amount of activity in this area in specific sectors – typically ones where large numbers of facts with relatively simple relationships need to be managed – the wider ambition, to make the web into a dataset with more and more explicit and machine-traversable links and ontologies, seems to have become an academic data-science backwater, rather than a serious live project, despite being officially part of the standards promoted by W3.org – the body responsible for web standards.
I’ve been looking into this recently as part of my work with the DadaMac Foundation. This is at present a tiny organisation that has, through patient and dedicated work seeking effective ways to help a few indigenous development projects in sub-Saharan Africa, developed a model for supporting development work that has enormous promise. I’ll write more about DadaMac another time (it’s a disruptive digital project, as well as a deeply humane one), but for now, one plank of their project is to capture the hard-won learning from each project and make that easily available to future projects.
Exactly – a knowledge base that can be effectively searched, and which produces highly relevant results across a range of sources. The Semantic web, right? That’s what I thought, but let me take you through the process…
DadaMac Knowledge Base – The ideal
Someone involved in a development project has a question. They don’t have time to conduct in-depth research, but they have a clear idea of their situation / need. The system would allow them to communicate that situation, whereupon it would direct them to any relevant entries.
The relevant implication of this for my present purpose is this: that information is structured in such a way as to make connections and relevance machine-discoverable from a user search.
the Semantic Web approach
The idea was that Semantic Web approaches would be useful here, but several problems were apparent, the most immediate being that the process of marking up text is clunky, onerous and fraught with problems. I will describe two serious ones;
- Ambiguity / indistinct terminology – it is fairly easy to see that Berlin should be described as the capital of Germany, but there are many situations where ambiguity will be present – particularly when we are describing new modes of practices across cultural boundaries, where people may not be using their first language. Take a solar panel – is it a ‘solar thermal panel’, ‘solar PV’, ‘solar photovoltaic panel’, ‘photovoltaic panel’, ‘solar cell’? Should all these be equated, or differentiated? Who decides? When? Once a decision is made, whose responsibility is it to trawl all the previously entered data to ensure compatibility? This is difficult enough with wikipedia, one of the most valued and visited sites on the internet, with a well-funded foundation behind it, which aspires to nothing as ambitious as a discovery agent (an attempt to use the content of wikipedia as the raw material for a semantically queriable encyclopedia was made, but seems to have been abandoned in 2012). Another example (unintentionally hilarious) is that, in different documents about Semantic Web practice, the elements of the ‘triple’ are not called Subject :: Predicate :: Object, but named as Individual :: Property :: Individual – so that even in the central documents of a project dedicated to cross-site consistency, there is ambiguity (it’s actually much worse than that).
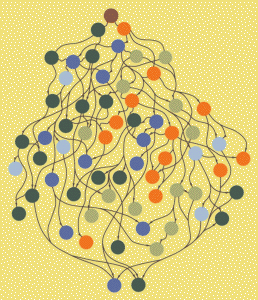
- Unsuitability for ‘mapping’ real-world structures – this is more fundamental. Semantic Web techniques are founded in hierarchical, tree-like structures, where every concept is in a singular relationship to some larger concept (within a particular context, at least). Thus, within the context of ‘The Beatles’, ‘John Lennon’ can only be identified as having one role at a time, so that if we identify him as a ‘Member’, he cannot at the same time be a ‘Guitarist’, ‘Singer’ or ‘Songwriter’, let alone as ‘the Political One’, or ‘the Angry One’, or …
This is a problem that crops up time and again in attempts to formalise information structures – it appears to be the ‘logical’ approach – but the real world is complex and messy, and is impossible adequately to map by means of such rigid, ‘tree-like’ structures, where each twig joins only to one larger branch, and so on until you reach the trunk.
The people who develop Semantic Web tools and approaches are, of course, highly intelligent, and recognise the problems discussed above. Unfortunately, their approach seems to be to bolt additional complexity onto the fundamentally reductive framework they started with. However, as far as I can see, this just makes a nightmare out of representing perfectly (human-) graspable sets of relationships, such as John Lennon’s to the Beatles, as ever more work is required of the producer of the original material who is required to enter more and more metadata using increasingly unnatural syntax and symbols (according to w3.org, the body responsible for web standards, and who set the standards for the Semantic Web, this abstruse 2006 document is the latest word on addressing issues like these – it is unclear whether they have been implemented).
A pattern approach
Frankly, I began to be appalled at the inadequacy of the approach to modelling real world information proposed by the Semantic Web project.
Christopher Alexander, creator of Pattern Languages, identified this issue through deep personal experience during his work on San Francisco’s metro network in the late 1960s, and clarified it in an essay – ‘A City is not a tree‘, which I consider should be a foundational text in this area. His basic point is that those multiple, simultaneous linkages between elements of any complex network must all be acknowledged in any model that is to be more than trivially useful. He proposes a model which is still hierarchical (a City has Districts, Districts have Areas and Roads, Areas have Buildings and Open Spaces…), but which allows for linkages across hierarchy levels (City has Buildings, Areas have Roads, Buildings have Open Spaces…).
The resulting structure is more complex, harder to navigate in an abstract way, but, crucially, still allows us to focus on elements (each is a Pattern) one at a time when we need to, while never letting us forget the web of relationships which are implicated (interestingly, according to the abstract of this paper comparing graphical representations of ontologies, tree-like visualisations were ‘more organized and familiar to novice users’, while graph visualisation was ‘more controllable and intuitive without visual redundancy, particularly for ontologies with multiple inheritance’).

From this perspective, I would characterise the Semantic Web approach as one of those traps that a computer science approach lays for us all the time, where we suddenly see that everything – yes, EVERYTHING! can be approached in terms of this system that we have just conceived of – it’s a sort of mad scientist moment, in the throes of which we lose all human perspective as to the rationality of seeing everything (yes EVERYTHING, I tell you! <cackles madly>) through a single lens.
It is an approach which seeks to atomise all concepts and relationships, and then rebuild them from scratch. Such approaches tend not to end well. In his one-paragraph story ‘On Rigour in Science‘, Jorge Luis Borges describes an empire where mapmakers had achieved such precision that;
“the Colleges of Cartographers set up a Map of the Empire which had the size of the Empire itself and coincided with it point by point. Less Addicted to the Study of Cartography, Succeeding Generations understood that this widespread Map was Useless and not without Impiety they abandoned it to the Inclemencies of the Sun and of the Winters. In the deserts of the West some mangled Ruins of the Map lasted on, inhabited by Animals and Beggars; in the whole Country there are no other relics of the disciples of Geography.”[1]
The work needed to prepare a body of information for Semantic Web approach is similarly disproportionate.
You need to maintain a separate ‘ontology’ file, which consists entirely of non human readable, code-like relationships, which must potentially be updated to cope with every single item of content, in case it contains new words, concepts or relationships – even if these are the same ones you have already codified, but use different words or verbal structures. And at the same time, your content authors (or a separate tier of editors) must annotate each piece of content to label each concept, relationship, object, and relate it to the ontology. The idea that a small charity, pulling itself up by its bootstraps, could devote the required resources to this is laughable – for one devastating reason above all – that, even if the resources were available, none of the information would be the slightest use to anyone until the ontology and labelling project was substantially complete. By which time, of course, a whole slew of new information would have arrived, and need labelling…
By contrast, a Pattern Language approach carefully identifies recurring patterns within the whirl of a dynamic, complex system – like vortices downstream of a rock in a stream, they are always there, but never exactly the same. Each of these patterns can be addressed in three ways – as a relatively self-contained whole, which can be addressed in its own terms, as a constituent element of a larger pattern, and as something built up from smaller wholes.
This approach supports a structured understanding of complex systems that can, crucially, be understood at a number of levels, that allows coherent collections of issues to be treated in relative isolation, while always maintaining the full gamut of connections to other issues, at larger and smaller scales.
My advice to DadaMac will be to develop a patterned approach to its knowledge base – starting off with a few clearly identifiable large scale phenomena, sketching them loosely to start with, with the complexities of smaller scale patterns unexamined as yet.
This allows for rational use of available cognitive and descriptive resources. In true agile mode, one can begin with the simplest adequate description of the objects, concepts and relationships involved, and go on incrementally to improve the scope, depth and accuracy of the model. In this way, the model of the totality of the knowledge available is useful from Day One, and increases in detail and viability thereafter.
As to the software tools we will use, that’s for another post. Thanks for reading!
